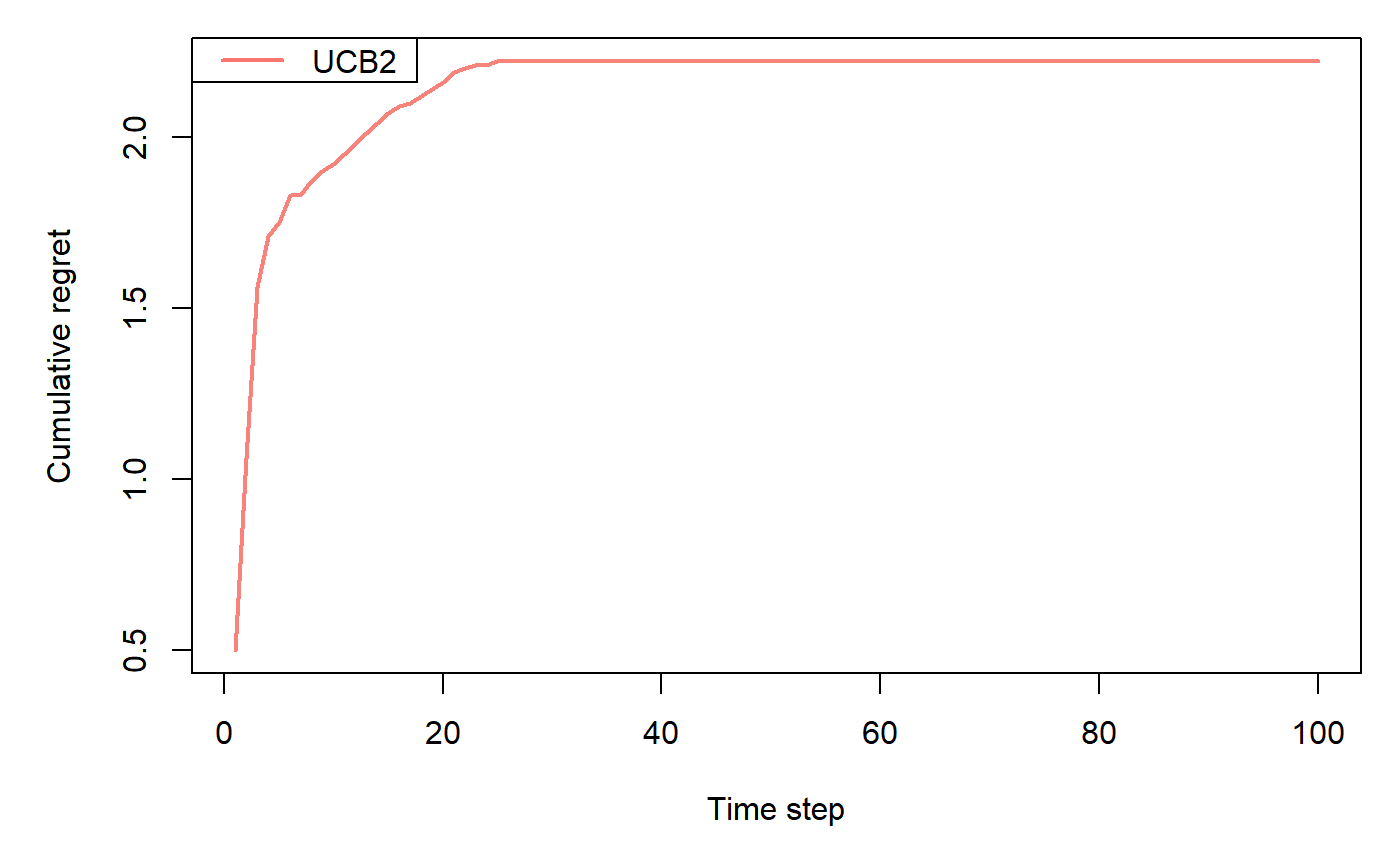
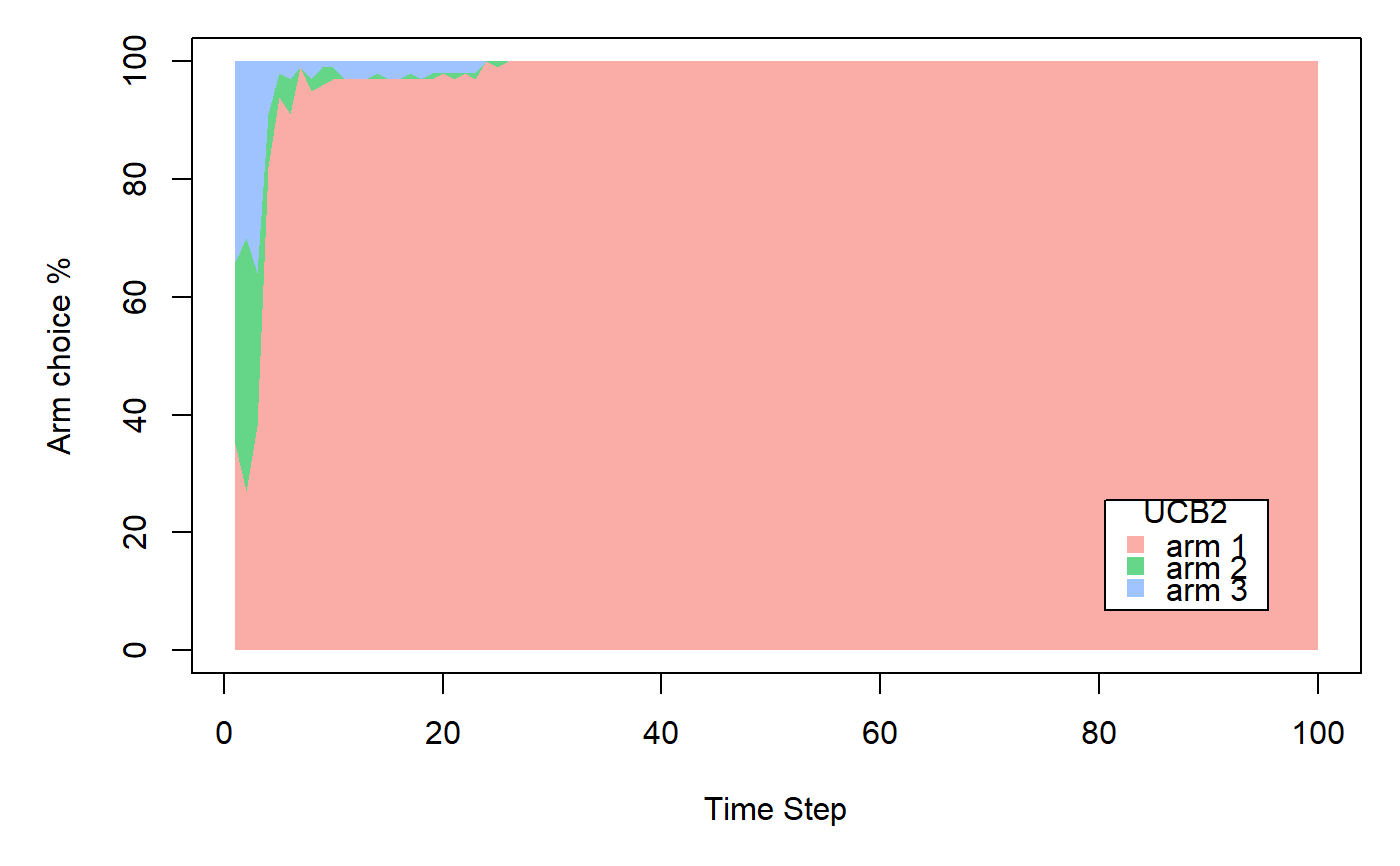
UCB policy for bounded bandits with plays divided in epochs.
Details
UCB2Policy constructs an optimistic estimate in the form of an Upper Confidence Bound to
create an estimate of the expected payoff of each action, and picks the action with the highest estimate.
If the guess is wrong, the optimistic guess quickly decreases, till another action has
the higher estimate.
Usage
policy <- UCB2Policy(alpha = 0.1)
Arguments
alphanumeric; Tuning parameter in the interval (0,1)
Methods
new(alpha = 0.1)Generates a new UCB2Policy object.
set_parameters()each policy needs to assign the parameters it wants to keep track of
to list self$theta_to_arms that has to be defined in set_parameters()'s body.
The parameters defined here can later be accessed by arm index in the following way:
theta[[index_of_arm]]$parameter_name
get_action(context)here, a policy decides which arm to choose, based on the current values of its parameters and, potentially, the current context.
set_reward(reward, context)in set_reward(reward, context), a policy updates its parameter values
based on the reward received, and, potentially, the current context.
References
Auer, P., Cesa-Bianchi, N., & Fischer, P. (2002). Finite-time analysis of the multiarmed bandit problem. Machine learning, 47(2-3), 235-256.
See also
Core contextual classes: Bandit, Policy, Simulator,
Agent, History, Plot
Bandit subclass examples: BasicBernoulliBandit, ContextualLogitBandit,
OfflineReplayEvaluatorBandit
Policy subclass examples: EpsilonGreedyPolicy, ContextualLinTSPolicy
Examples
horizon <- 100L simulations <- 100L weights <- c(0.9, 0.1, 0.1) policy <- UCB2Policy$new() bandit <- BasicBernoulliBandit$new(weights = weights) agent <- Agent$new(policy, bandit) history <- Simulator$new(agent, horizon, simulations, do_parallel = FALSE)$run()#>#>#>#>#>#>#>