library(contextual)
policy <- EpsilonGreedyPolicy$new(epsilon = 0.1)
bandit <- BasicBernoulliBandit$new(weights = c(0.6, 0.1, 0.1))
agent <- Agent$new(policy,bandit)
simulator <- Simulator$new(agents = agent,
horizon = 100,
simulations = 1000)
history <- simulator$run()
plot(history, type = "cumulative", regret = TRUE, disp = "ci",
traces_max = 100, traces_alpha = 0.1, traces = TRUE)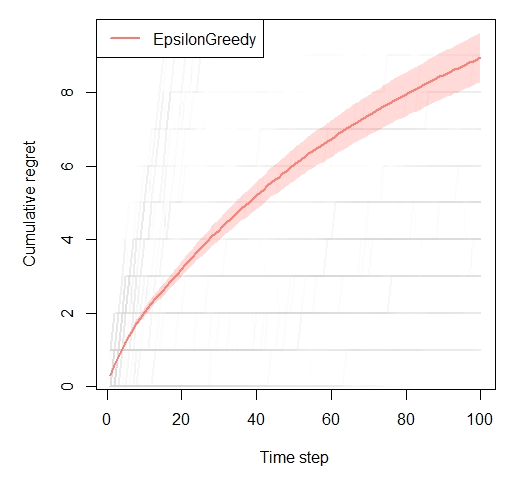
Agents:
EpsilonGreedy
Cumulative regret:
agent t sims cum_regret cum_regret_var cum_regret_sd
EpsilonGreedy 100 1000 8.951 116.7133 10.80339
Cumulative reward:
agent t sims cum_reward cum_reward_var cum_reward_sd
EpsilonGreedy 100 1000 51.09 141.6215 11.90048
Cumulative reward rate:
agent t sims cur_reward cur_reward_var cur_reward_sd
EpsilonGreedy 100 1000 0.5109 1.416215 0.1190048