Maintainers
Robin van Emden: author, maintainer Maurits Kaptein: supervisor
* Tilburg University / Jheronimus Academy of Data Science.
If you encounter a clear bug, please file a minimal reproducible example on GitHub.
R package facilitating the simulation and evaluation of context-free and contextual Multi-Armed Bandit policies.
The package has been developed to:
Package links:
To install contextual from CRAN:
install.packages('contextual')
To install the development version (requires the devtools package):
install.packages("devtools") devtools::install_github('Nth-iteration-labs/contextual')
When working on or extending the package, clone its GitHub repository, then do:
install.packages("devtools") devtools::install_deps(dependencies = TRUE) devtools::build() devtools::reload()
clean and rebuild…
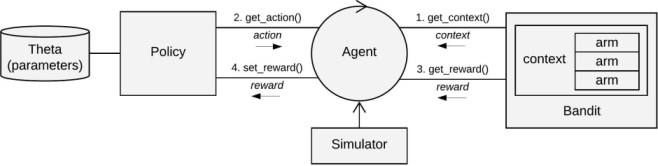
Contextual consists of six core classes. Of these, the Bandit and Policy classes are subclassed and extended when implementing custom (synthetic or offline) bandits and policies. The other four classes (Agent, Simulator, History, and Plot) are the workhorses of the package, and generally need not be adapted or subclassed.
See the demo directory for practical examples and replications of both synthetic and offline (contextual) bandit policy evaluations.
When seeking to extend contextual, it may also be of use to review “Extending Contextual: Frequently Asked Questions”, before diving into the source code.
How to replicate figures from two introductory context-free Multi-Armed Bandits texts:
Basic, context-free multi-armed bandit examples:
Examples of both synthetic and offline contextual multi-armed bandit evaluations:
Offline Evaluation Data Set - Bootstrapped Replay Bandit: Carskit DePaul Movies
Offline Evaluation Data Set - Lookup Table Replay Bandit: MovieLens 10M
An example how to make use of the optional theta log to create interactive context-free bandit animations:
Some more extensive vignettes to get you started with the package:
Paper offering a general overview of the package’s structure & API:
Overview of contextual’s growing library of contextual and context-free bandit policies:
| General | Context-free | Contextual | Other |
|---|---|---|---|
| Random Oracle Fixed |
Epsilon-Greedy Epsilon-First UCB1, UCB2 Thompson Sampling BootstrapTS Softmax Gradient Gittins |
CMAB Naive Epsilon-Greedy Epoch-Greedy LinUCB (General, Disjoint, Hybrid) Linear Thompson Sampling ProbitTS LogitBTS GLMUCB |
Lock-in Feedback (LiF) |
Overview of contextual’s bandit library:
| Basic Synthetic | Contextual Synthetic | Offline | Continuous |
|---|---|---|---|
| Basic Bernoulli Bandit Basic Gaussian Bandit |
Contextual Bernoulli Contextual Logit Contextual Hybrid Contextual Linear Contextual Wheel |
Replay Evaluator Bootstrap Replay Propensity Weighting Direct Method Doubly Robust |
Continuum |
By default, “contextual” uses R’s built-in parallel package to facilitate parallel evaluation of multiple agents over repeated simulation. See the demo/alternative_parallel_backends directory for several alternative parallel backends:
Robin van Emden: author, maintainer Maurits Kaptein: supervisor
* Tilburg University / Jheronimus Academy of Data Science.
If you encounter a clear bug, please file a minimal reproducible example on GitHub.
