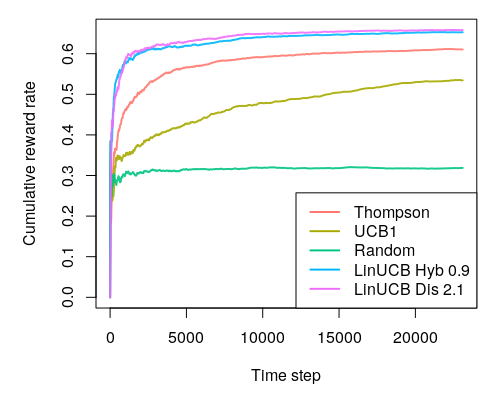
library(contextual) library(data.table) library(splitstackshape) library(RCurl) # Import MovieLens ml-10M ------------------------------------------------------------------------ # Info: https://d1ie9wlkzugsxr.cloudfront.net/data_movielens/ml-10M/README.html movies_dat <- "http://d1ie9wlkzugsxr.cloudfront.net/data_movielens/ml-10M/movies.dat" ratings_dat <- "http://d1ie9wlkzugsxr.cloudfront.net/data_movielens/ml-10M/ratings.dat" movies_dat <- readLines(movies_dat) movies_dat <- gsub( "::", "~", movies_dat ) movies_dat <- paste0(movies_dat, collapse = "\n") movies_dat <- fread(movies_dat, sep = "~", quote="") setnames(movies_dat, c("V1", "V2", "V3"), c("MovieID", "Name", "Type")) movies_dat <- splitstackshape::cSplit_e(movies_dat, "Type", sep = "|", type = "character", fill = 0, drop = TRUE) movies_dat[[3]] <- NULL ratings_dat <- RCurl::getURL(ratings_dat) ratings_dat <- readLines(textConnection(ratings_dat)) ratings_dat <- gsub( "::", "~", ratings_dat ) ratings_dat <- paste0(ratings_dat, collapse = "\n") ratings_dat <- fread(ratings_dat, sep = "~", quote="") setnames(ratings_dat, c("V1", "V2", "V3", "V4"), c("UserID", "MovieID", "Rating", "Timestamp")) all_movies <- ratings_dat[movies_dat, on=c(MovieID = "MovieID")] all_movies <- na.omit(all_movies,cols=c("MovieID", "UserID")) rm(movies_dat,ratings_dat) # Data wrangling -------------------------------------------------------------------------------- all_movies[, UserID := as.numeric(as.factor(UserID))] count_movies <- all_movies[,.(MovieCount = .N), by = MovieID] top_50 <- as.vector(count_movies[order(-MovieCount)][1:50]$MovieID) not_50 <- as.vector(count_movies[order(-MovieCount)][51:nrow(count_movies)]$MovieID) top_50_movies <- all_movies[MovieID %in% top_50] # ----------------------------------------------------------------------------------------------- # Create feature lookup tables - to speed up, MovieID and UserID are # ordered and lined up with the (dt/matrix) default index. # Arm features # MovieID of top 50 ordered from 1 to N as arms (Arms always start from 1) top_50_movies[, MovieID := as.numeric(as.factor(MovieID))] arm_features <- top_50_movies[,head(.SD, 1),by = MovieID][,c(1,6:24)] setorder(arm_features,MovieID) # User features # Count of categories for non-top-50 movies normalized per user user_features <- all_movies[MovieID %in% not_50] user_features[, c("MovieID", "Rating", "Timestamp", "Name"):=NULL] user_features <- user_features[, lapply(.SD, sum, na.rm=TRUE), by=UserID ] user_features[, total := rowSums(.SD, na.rm = TRUE), .SDcols = 2:20] user_features[, 2:20 := lapply(.SD, function(x) x/total), .SDcols = 2:20] user_features$total <- NULL # Add users that were not in the set of non-top-50 movies (4 in 10m dataset) all_users <- as.data.table(unique(all_movies$UserID)) user_features <- user_features[all_users, on=c(UserID = "V1")] user_features[is.na(user_features)] <- 0 setorder(user_features,UserID) # ---------------------------------------------------------------------------------------------- rm(all_movies, not_50, top_50, count_movies) # ---------------------------------------------------------------------------------------------- # Contextual format top_50_movies[, t := .I] top_50_movies[, sim := 1] top_50_movies[, agent := "Offline"] top_50_movies[, choice := MovieID] top_50_movies[, reward := ifelse(Rating <= 4, 0, 1)] setorder(top_50_movies,Timestamp,Name) # Run simulation -------------------------------------------------------------------------------- simulations <- 1 horizon <- 1000 #nrow(top_50_movies) bandit <- OfflineLookupReplayEvaluatorBandit$new(top_50_movies, k = 50, unique_col = "UserID", shared_lookup = arm_features, unique_lookup = user_features) agents <- list(Agent$new(ThompsonSamplingPolicy$new(), bandit, "Thompson"), Agent$new(UCB1Policy$new(), bandit, "UCB1"), Agent$new(RandomPolicy$new(), bandit, "Random"), Agent$new(LinUCBHybridOptimizedPolicy$new(0.9), bandit, "LinUCB Hyb 0.9"), Agent$new(LinUCBDisjointOptimizedPolicy$new(2.1), bandit, "LinUCB Dis 2.1")) simulation <- Simulator$new( agents = agents, simulations = simulations, horizon = horizon, reindex = TRUE ) results <- simulation$run() plot(results, type = "cumulative", regret = FALSE, rate = TRUE, legend_position = "topleft")