Details
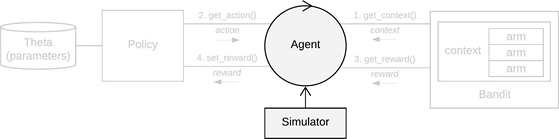
Controls the running of one Bandit and Policy
pair over t = {1, ..., T} looping over, consecutively,
bandit$get_context(), policy$get_action(), bandit$get_reward() and policy$set_reward()
for each time step t.
Schematic
Usage
agent <- Agent$new(policy, bandit, name=NULL, sparse = 0.0)
Arguments
policyPolicy instance.
banditBandit instance.
namecharacter; sets the name of the Agent. If NULL (default), Agent generates a name
based on its Policy instance's name.
sparsenumeric; artificially reduces the data size by setting a sparsity level for the current
Bandit and Policy pair.
When set to a value between 0.0 (default) and 1.0 only a fraction sparse of
the Bandit's data is randomly chosen to be available to improve the Agent's
Policy through policy$set_reward.
Methods
new()generates and instantializes a new Agent instance.
do_step()advances a simulation by one time step by consecutively calling bandit$get_context(),
policy$get_action(), bandit$get_reward() and policy$set_reward().
Returns a list of lists containing context, action, reward and theta.
set_t(t)integer; sets the current time step to t.
get_t()returns current time step t.
See also
Core contextual classes: Bandit, Policy, Simulator,
Agent, History, Plot
Bandit subclass examples: BasicBernoulliBandit, ContextualLogitBandit,
OfflineReplayEvaluatorBandit
Policy subclass examples: EpsilonGreedyPolicy, ContextualLinTSPolicy