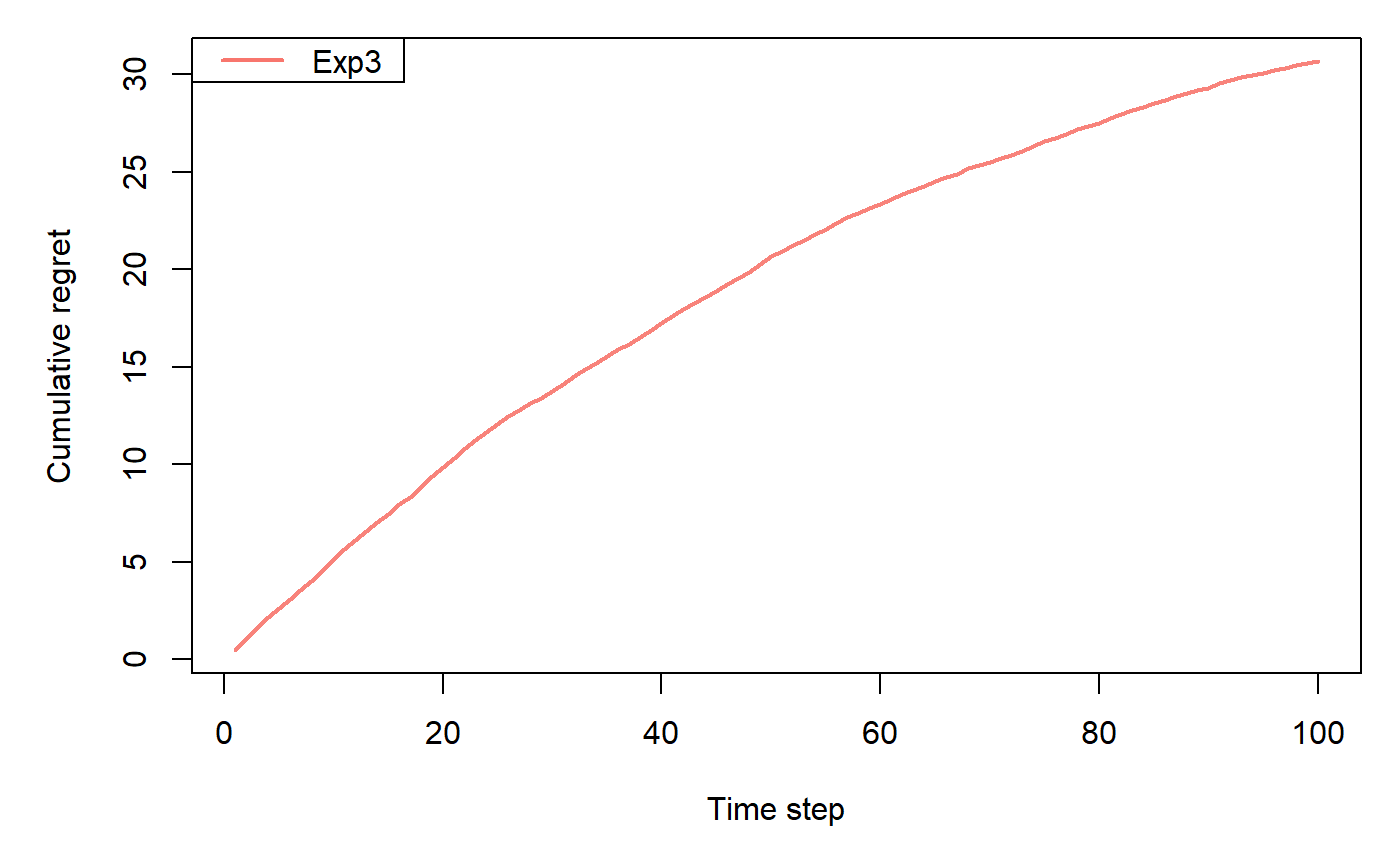
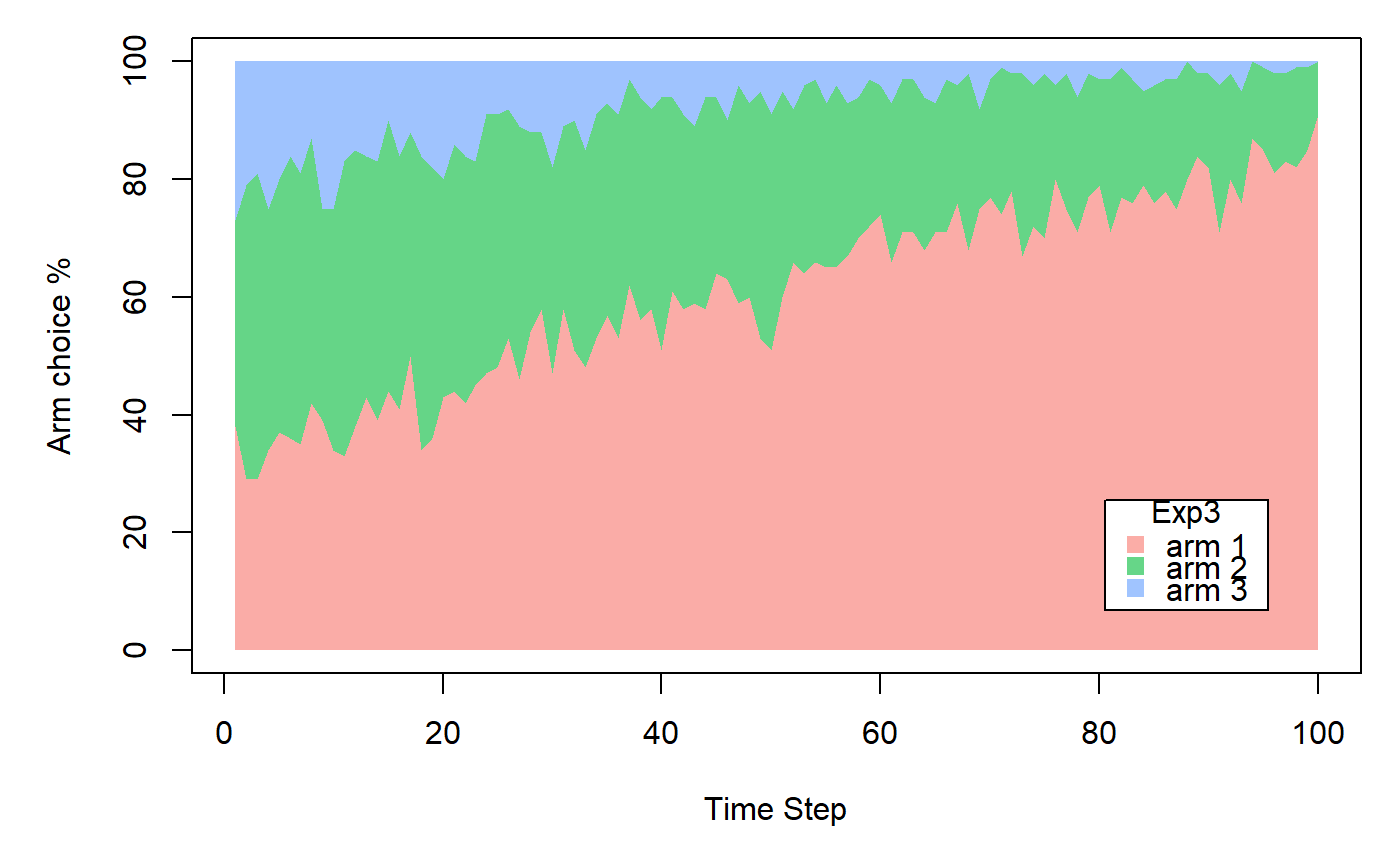
In Exp3Policy, "Exp3" stands for "Exponential-weight algorithm for Exploration and Exploitation".
It makes use of a distribution over probabilities that is is a mixture of a
uniform distribution and a distribution which assigns to each action
a probability mass exponential in the estimated cumulative reward for that action.
Usage
policy <- Exp3Policy(gamma = 0.1)
Arguments
gammadouble, value in the closed interval (0,1], controls the exploration - often referred to as the learning rate
namecharacter string specifying this policy. name
is, among others, saved to the History log and displayed in summaries and plots.
Methods
new(gamma = 0.1)Generates a new Exp3Policy object. Arguments are defined in the Argument section above.
set_parameters()each policy needs to assign the parameters it wants to keep track of
to list self$theta_to_arms that has to be defined in set_parameters()'s body.
The parameters defined here can later be accessed by arm index in the following way:
theta[[index_of_arm]]$parameter_name
get_action(context)here, a policy decides which arm to choose, based on the current values of its parameters and, potentially, the current context.
set_reward(reward, context)in set_reward(reward, context), a policy updates its parameter values
based on the reward received, and, potentially, the current context.
References
Auer, P., Cesa-Bianchi, N., Freund, Y., & Schapire, R. E. (2002). The nonstochastic multi-armed bandit problem. SIAM journal on computing, 32(1), 48-77. Strehl, A., & Littman, M. (2004). Exploration via model based interval estimation. In International Conference on Machine Learning, number Icml.
Strehl, A., & Littman, M. (2004). Exploration via model based interval estimation. In International Conference on Machine Learning, number Icml.
See also
Core contextual classes: Bandit, Policy, Simulator,
Agent, History, Plot
Bandit subclass examples: BasicBernoulliBandit, ContextualLogitBandit,
OfflineReplayEvaluatorBandit
Policy subclass examples: EpsilonGreedyPolicy, ContextualLinTSPolicy
Examples
horizon <- 100L simulations <- 100L weights <- c(0.9, 0.1, 0.1) policy <- Exp3Policy$new(gamma = 0.1) bandit <- BasicBernoulliBandit$new(weights = weights) agent <- Agent$new(policy, bandit) history <- Simulator$new(agent, horizon, simulations, do_parallel = FALSE)$run()#>#>#>#>#>#>#>